Neuroinformatics Group






















Universität Bielefeld › Technische Fakultät › NI
Search
Computer Vision
Vision is a highly developed ability both in animals and in man. Exploring computer algorithms for the recognition of patterns and of 3D shapes and using eye-tracking experiments for investigating the control of visual attention can provide insights into the different processing steps underlying vision. This is a basis to synthesize important strategies of biological vision systems, among them visual learning, perceptual grouping and active gaze control in artificial vision systems, in this way providing an important ability for many application fields.
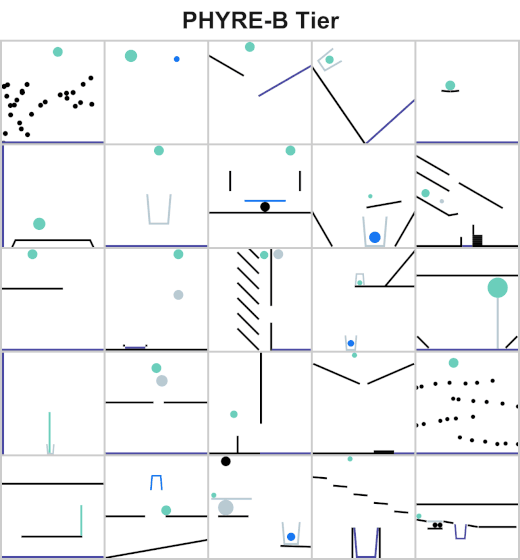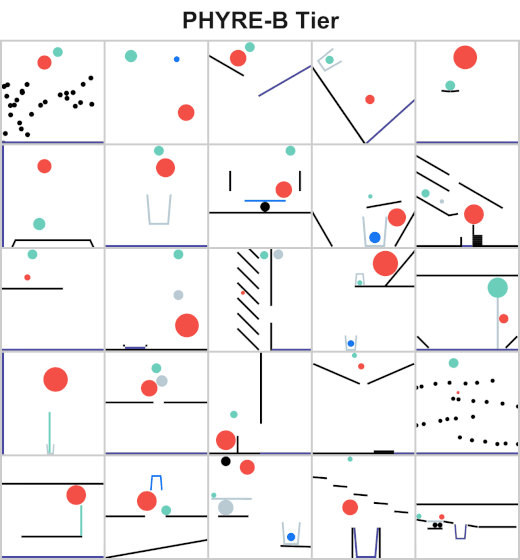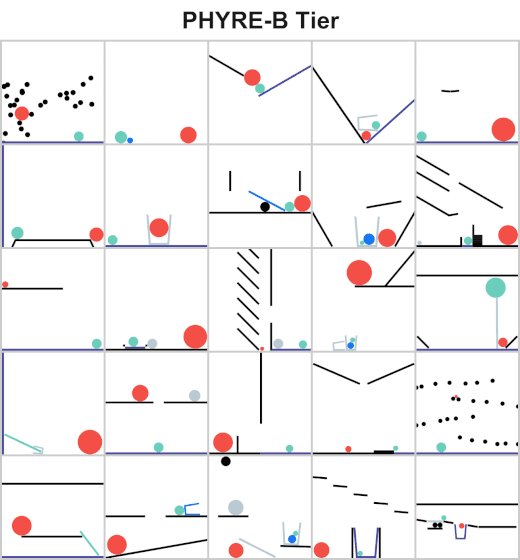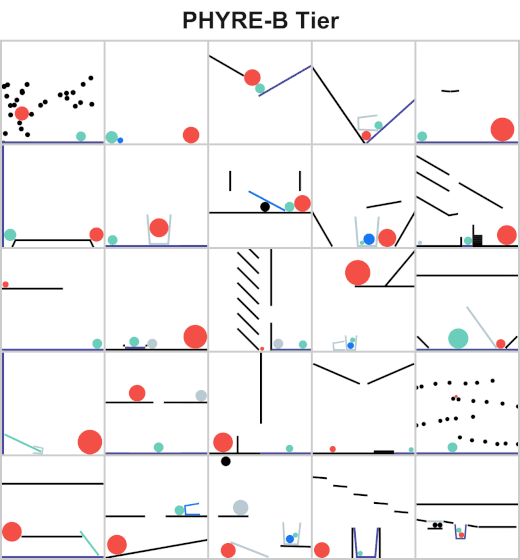 Understanding and reasoning about physics is an important ability of intelligent agents. We are developing an AI agent capable of solving physical reasoning tasks. If you would like to know more about this project/thesis opportunity, check the websites [1][2] or contact Dr. Andrew Melnik.
Understanding and reasoning about physics is an important ability of intelligent agents. We are developing an AI agent capable of solving physical reasoning tasks. If you would like to know more about this project/thesis opportunity, check the websites [1][2] or contact Dr. Andrew Melnik.

 Computer Vision and processing of multimodal sensor data is very important to take Smart Homes to the next level. An intelligent everyday environment should be aware of its residents. It should understand their actions and ideally even be able to predict their behavior. In the
Computer Vision and processing of multimodal sensor data is very important to take Smart Homes to the next level. An intelligent everyday environment should be aware of its residents. It should understand their actions and ideally even be able to predict their behavior. In the  A major pre-requisite for many robotics tasks is to identify and localize objects within scenes. Our model-free approaches to scene segmentation employs RGBD cameras to segmented highly cluttered scenes in real-time (30 Hz). To this end, we first identify smooth object surfaces and subsequently combine them to form object hypotheses employing basic heuristics such has convexity, shape alignment and color similarity.
A major pre-requisite for many robotics tasks is to identify and localize objects within scenes. Our model-free approaches to scene segmentation employs RGBD cameras to segmented highly cluttered scenes in real-time (30 Hz). To this end, we first identify smooth object surfaces and subsequently combine them to form object hypotheses employing basic heuristics such has convexity, shape alignment and color similarity.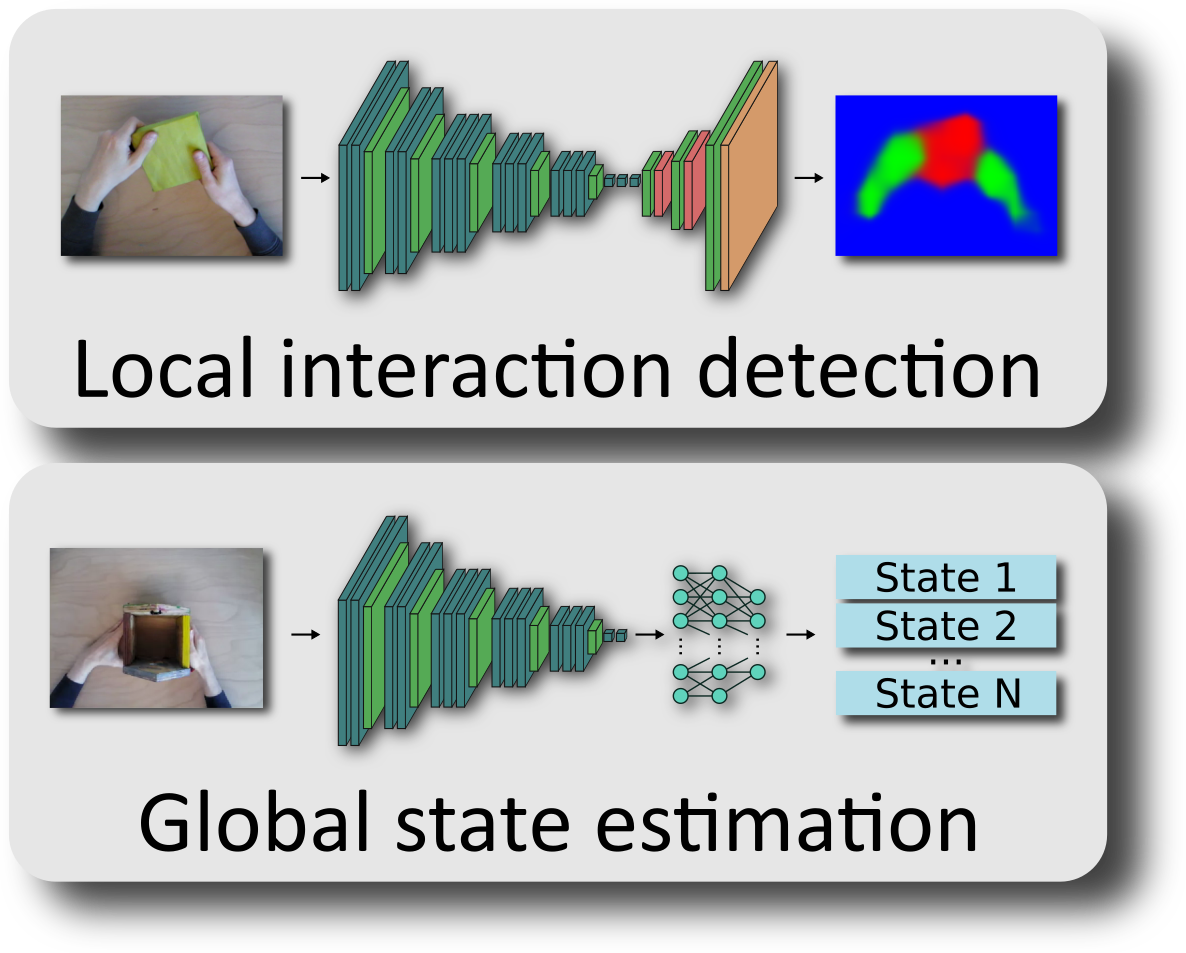 The visual detection and recognition of human actions by technical systems is a fundamental problem with many applications the human-computer interaction domain. Activities involving hand-object interactions and action sequences in goal-oriented tasks, such as manufacturing work, pose a particular challenge. We use deep learning to detect and recognize such actions in real-time, and we propose an assistance system that provides the user with feedback and guidance based on the recognized actions.
The visual detection and recognition of human actions by technical systems is a fundamental problem with many applications the human-computer interaction domain. Activities involving hand-object interactions and action sequences in goal-oriented tasks, such as manufacturing work, pose a particular challenge. We use deep learning to detect and recognize such actions in real-time, and we propose an assistance system that provides the user with feedback and guidance based on the recognized actions. Manipulation of paper is a rich domain of manual intelligence that we encounter in many daily tasks. The present project attempts to analyse and implement the "web" of visuo-motor coordination skills to endow an anthropomorphic robot hand with the ability to manipulate paper (and paper-like objects) in a variety of situations of increasing complexity. This will include aspects such as modeling interaction with compliant objects, action based representation as well as bimanual coordination to enable object transformations such as tearing and folding.
Manipulation of paper is a rich domain of manual intelligence that we encounter in many daily tasks. The present project attempts to analyse and implement the "web" of visuo-motor coordination skills to endow an anthropomorphic robot hand with the ability to manipulate paper (and paper-like objects) in a variety of situations of increasing complexity. This will include aspects such as modeling interaction with compliant objects, action based representation as well as bimanual coordination to enable object transformations such as tearing and folding. While language provides us with a concise code capturing much of the movement complexity of our mouth, we still lack a comparable representation for the movement of our hands. This project aims to create a database of human hand interaction patterns from a variety of multimodal data sources. An associated goal is to develop methods for the clustering of captured trajectory data into physics-based models of manual interaction. We hope that the resulting database can make a contribution towards a better grounding of control strategies for anthropomorphic robot hands and develop for robotics a similar utility as the WordNet database has for linguistics.
While language provides us with a concise code capturing much of the movement complexity of our mouth, we still lack a comparable representation for the movement of our hands. This project aims to create a database of human hand interaction patterns from a variety of multimodal data sources. An associated goal is to develop methods for the clustering of captured trajectory data into physics-based models of manual interaction. We hope that the resulting database can make a contribution towards a better grounding of control strategies for anthropomorphic robot hands and develop for robotics a similar utility as the WordNet database has for linguistics. Unlike most existing approaches to the grasp selection task for anthropomorphic robot hands, this vision-based project aims for a solution, which does not depend on an a-priori known 3D shape of the object. Instead it uses a decomposition of the object view (obtained from mono or stereo cameras) into local, grasping-relevant shape primitives, whose optimal grasp type and approach direction are known or learned beforehand. Based on this decomposition a list of possible grasps can be generated and ordered according to the anticipated overall grasp quality.
Unlike most existing approaches to the grasp selection task for anthropomorphic robot hands, this vision-based project aims for a solution, which does not depend on an a-priori known 3D shape of the object. Instead it uses a decomposition of the object view (obtained from mono or stereo cameras) into local, grasping-relevant shape primitives, whose optimal grasp type and approach direction are known or learned beforehand. Based on this decomposition a list of possible grasps can be generated and ordered according to the anticipated overall grasp quality. An important capability for robotic vision systems is to distinguish objects from their background. In this project we study figure-ground segmentation for online object learning in an unconstrained interaction scenario: An object of interests is presented to the robot by hand in a dynamically changing, cluttered background. Employing attention mechanism and color-based clustering, we can successfully segment the object.
An important capability for robotic vision systems is to distinguish objects from their background. In this project we study figure-ground segmentation for online object learning in an unconstrained interaction scenario: An object of interests is presented to the robot by hand in a dynamically changing, cluttered background. Employing attention mechanism and color-based clustering, we can successfully segment the object. In this project we are developing a system that is aimed to overcome a major limitation of current computer vision: The specialization of vision architectures to one special task. In this approach, artificial neural networks (ANN) are applied to learn the appearance of objects from samples images. By this means, the costly designing of geometric object models can be avoided. This work is realized in the framework NESSY (NEural viSion SYstem), a software package that allows an easy design and visualization of image processing systems.
In this project we are developing a system that is aimed to overcome a major limitation of current computer vision: The specialization of vision architectures to one special task. In this approach, artificial neural networks (ANN) are applied to learn the appearance of objects from samples images. By this means, the costly designing of geometric object models can be avoided. This work is realized in the framework NESSY (NEural viSion SYstem), a software package that allows an easy design and visualization of image processing systems.  Active Vision considers vision as a process of active data aquisition, i.e. actively pointing the cameras towards interesting regions within the scene, eventually changing zoom as well.
Active Vision considers vision as a process of active data aquisition, i.e. actively pointing the cameras towards interesting regions within the scene, eventually changing zoom as well.  In order to handle the ever growing amount of digital images, in this project we develop a content-based image retrieval system offering the possibility to efficiently search large image databases by automatically finding similar images. To this end, we use automatically extracted image features, derived from a selection of image candidates.
In order to handle the ever growing amount of digital images, in this project we develop a content-based image retrieval system offering the possibility to efficiently search large image databases by automatically finding similar images. To this end, we use automatically extracted image features, derived from a selection of image candidates.  Common webcams yield a huge amount of images, but most of them are quite boring for lack of individual fascinating entities. In this project we analyse approaches of common image and video retrieval to develop a system for filtering interesting images shot by a webcam.
Common webcams yield a huge amount of images, but most of them are quite boring for lack of individual fascinating entities. In this project we analyse approaches of common image and video retrieval to develop a system for filtering interesting images shot by a webcam. 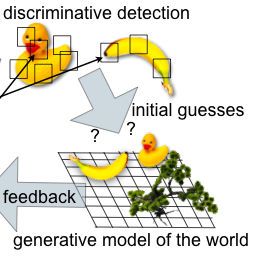 The ultimate goal of biological vision systems is to infer knowledge about the outside world that is relevant for the system in order to interact with its environment. Therefore, it is not sufficient to just determine the category or the mere object identity. Many variables of interest must be estimated, for example the distance towards an object, the size, orientation, velocity or even such abstract variables like the mood of another animal. In this project we aim to extend existing invariant recognition approaches by using a new approach to hierarchical generative networks in order to implicitly represent (and learn) visual objects, and finally even scenes.
The ultimate goal of biological vision systems is to infer knowledge about the outside world that is relevant for the system in order to interact with its environment. Therefore, it is not sufficient to just determine the category or the mere object identity. Many variables of interest must be estimated, for example the distance towards an object, the size, orientation, velocity or even such abstract variables like the mood of another animal. In this project we aim to extend existing invariant recognition approaches by using a new approach to hierarchical generative networks in order to implicitly represent (and learn) visual objects, and finally even scenes.